概要
ANTLRとPython、VBAを利用して、Javaのソースコードから全条件文を抽出する方法を紹介します。フラグやイベントなどでの状態制御(条件分岐)を抽出・可視化することで、状態遷移表を作成することができます。

こんな方におすすめ
- 設計書や状態遷移表が存在せず、保守や派生開発で困っている
- スパゲティ状態のソースコードをリファクタリングしたい
- 設計書の状態遷移表通りに実装できているか検証したい
Javaのソースコードから状態遷移表のベースを作成する流れは、以下の通りです。
私のプログラムを実行していただくだけで状態遷移表のベースを出力することができますが、
Python・VBAを使ってカスタマイズすることで、よりきめ細やかな対応が可能になります。
- ANTLRとPythonを使ってJavaのソースコードを構文解析
- Javaのソースコードから全ての条件分岐を抽出
- 抽出した条件分岐をExcel VBAで整形
- 条件から状態を纏めて状態遷移表のベースを作成

語句説明
AST(Abstract Syntax Tree)とは
Wikipediaによると、抽象構文木の説明は以下になっています。
抽象構文木(英: abstract syntax tree、AST)は、通常の構文木(具象構文木あるいは解析木とも言う)から、言語の意味に関係ない情報を取り除き、意味に関係ある情報のみを取り出した(抽象した)木構造の木である。
プログラム言語における抽象構文木とは、プログラム言語の文法に従い、ソースコードを構造解析して木の形で表すことです。コンパイラには予め備わっている機能で、その解析結果に従って実行バイナリや中間ファイルを生成します。
例えば、以下のような例を見るとイメージしやすいかと思います。

出典:https://ist.ksc.kwansei.ac.jp/~ishiura/prevxcpl/ast.pdf
ANTLRとは
ANTLR(https://www.antlr.org/)とは、構文解析をするためのソースコードを自動生成するツールです。ANTLRでは、文法ファイル(.g4)を入力として、Python、Java、Go、JavaScriptなどのソースコードを出力できます。
出力されるソースコードは大きく3種類あります。
- Lexer:字句解析
プログラミング言語の文法で予約されている字句を解析します。
例えば、if、for、whiteなど、括弧 (...) {...} 等を含めて解析します。 - Parser:構文解析
入力する解析対象のソースコードを構文木に分解する処理を行います。 - Listener:イベントリスナー
Lexer、Parserを主に利用し、自然言語処理を行って構文解析をします。
その解析の過程で、構文木のノードが切り替わった際に知らせてくれるAPI群です。
例えば、「IF文が始まったよ~。条件は〇〇ね。」と知らせてくれます。
ポイント
紹介する方法は、ANTLRで生成されるソースコードのListenerを拡張して状態遷移表を生成します。
リバースエンジニアリングとは
Wikipediaによると、リバースエンジニアリングは以下のように説明されています。
リバースエンジニアリング(Reverse engineeringから。直訳すれば逆行工学という意味)とは、機械を分解したり、製品の動作を観察したり、ソフトウェアの動作を解析するなどして、製品の構造を分析し、そこから製造方法や動作原理、設計図などの仕様やソースコードなどを調査することを指す。
ソフトウェア開発では、製品に搭載するソフトウェアを開発する工程とは逆の工程で、ソースコードから設計書(今回は状態遷移図)を起こすことを指します。
リファクタリングとは
Wikipediaでは、リファクタリングは以下のように説明されています。
リファクタリング (refactoring) とは、コンピュータプログラミングにおいて、プログラムの外部から見た動作を変えずにソースコードの内部構造を整理することである。
これはそのままの意味になりますね。
ソフトウェアを開発中、スケジュールの遅延や急な仕様変更等で最終的なソースコードがスパゲティ状態!と言うことも珍しくありません。ソフトウェアの保守や次期開発に向けて内部構造を整理したりすることです。
ANTLRで構文解析のスクリプトを自動生成
※この部分は Qiita 5zm さんの記事を参考にしています。
ANTLRのダウンロード
ANTLRの構文解析スクリプトを生成する機能は、Javaのプログラムとして提供されています。
https://www.antlr.org/download/antlr-4.7.1-complete.jar をダウンロードして、任意のディレクトリに格納します。
文法ファイル(g4)のダウンロード
解析する対象のプログラミング言語の文法ファイル(g4)がANTLRのGitHubページで公開されています。
今回は、Javaの文法ファイルを https://github.com/antlr/grammars-v4/tree/master/java/java から取得します。
取得したファイル(JavaLexer.g4、JavaParser.g4)を任意のディレクトリに格納します。例えば、以下のような階層にしておくと分かりやすいです。
生成前
|- antlr-4.7.1-complete.jar
|- grammar/
| |- JavaLexer.g4
| |- JavaParser.g4
Lexer・Parser・Listenerの生成
ANTLRでPython3用のLexer(字句解析)、Parser(構文解析)、Listener(イベントリスナー)を自動生成するコマンドを以下に示します。
-Dlanguageオプションで、生成するスクリプトのプログラミング言語を指定することができます。Pythonの場合、Python3とPython2とで異なるので注意してください。
生成コマンド
java -jar antlr-4.7.1-complete.jar -Dlanguage=Python3 grammar\*.g4
上記のコマンドを実行すると、以下のようになっていると思います。
生成後
|- antlr-4.7.1-complete.jar
|- grammar/
| |- JavaLexer.g4
| |- JavaParser.g4
| |- JavaLexer.interp
| |- JavaLexer.py ★
| |- JavaLexer.tokens
| |- JavaParser.interp
| |- JavaParser.py ★
| |- JavaParser.tokens
| |- JavaParserListener.py ★
これでJavaのソースコード解析で必要となるスクリプトのソースコード(上記★)が手に入りました。
以降、このファイルを利用して独自の構文解析のプログラムを実装していきます。
構文解析用の独自プログラムを作成
開発の準備
PythonでANTLRを使うために、Pythonが動作する環境に antlr4-python3-runtime をインストールします。
command
pip install antlr4-python3-runtime
前述した通り、取得したい情報のListenerに独自のコードを埋め込んで拡張します。
今回はJavaクラスのメソッドに実装されている条件文の抽出ですので、以下の情報を取得します。
- メソッド名
- メソッドの戻り値のデータ型
- メソッドの引数名と型
- IF文のステートメント
- SWITCH文のステートメント
独自拡張部分の設計概要
基本的な考え方は、以下の通りです。
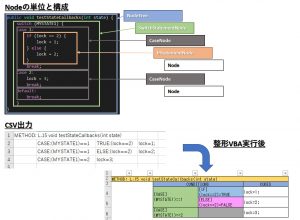
- Node(ノード)ツリーを構築して管理
- 構文解析が終わったら、Nodeの情報をCSVで出力
例えば、以下のようなJavaコードを構文解析した場合のNodeの単位と構成、CSV出力を例示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public class MyTest { public void testStateCallbacks(int state) { switch (MYSTATE1) { case 1: if (lock == 2) { lock = 1; } else { lock = 2; } break; case 2: lock = 3; break; default: break; } } } |
更新履歴(2020/11/22)
もとの MyTest.java に Java の構文エラーがあったため更新。
スポンサーリンク
クラス構成
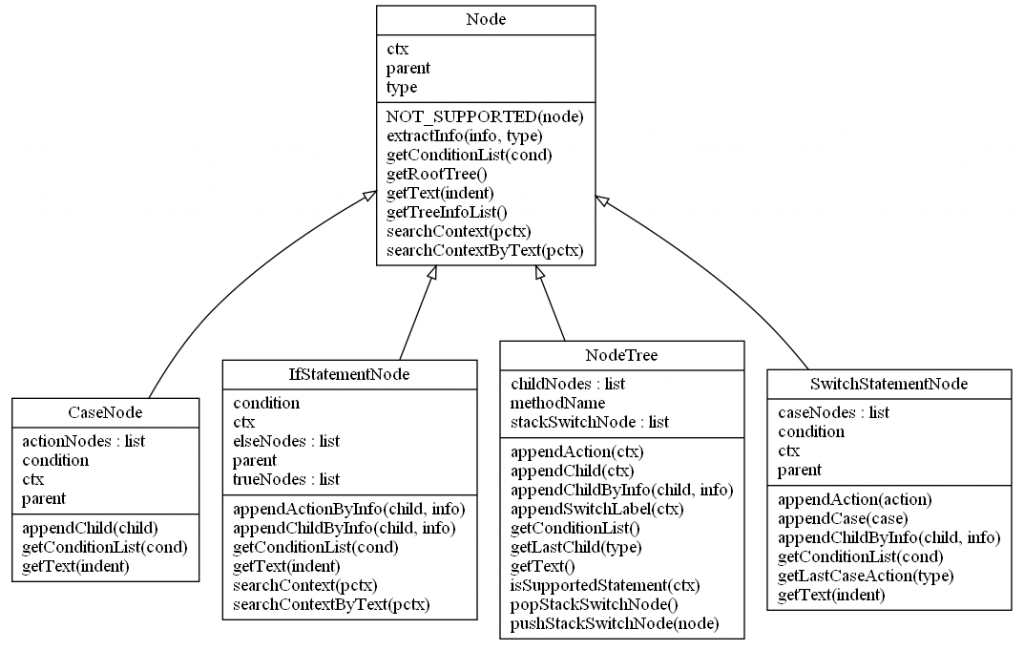
Pythonを使って独自拡張したNodeツリーを構成するクラスは、以下の通りです。
それぞれ順に解説していきます。
-

-
参考【手順】Pythonのクラス図を無料で自動生成する方法
Pythonの pyreverse と、dot 言語で記述されたグラフ構造を画像出力する Graphviz を使用し、Pythonのクラス図を無料で自動生成する方法。Windows、Unix(Ubuntu,Fedora等)両方の環境構築を記載。
続きを見る

ディレクトリ構成
ディレクトリ構成
|- ast_main.py
|- ast/
| |- JavaLexer.py
| |- JavaParser.py
| |- JavaParserListener.py
|- java/
| |- MyTest.java
|- myextend/
| |- AstProcessor.py
| |- CaseNode.py
| |- IfStatementNode.py
| |- Node.py
| |- NodeTree.py
| |- StatementListener.py
| |- SwitchStatementNode.py
ast_main.py が実行するスクリプトのメインで、ast/ ディレクトリ下に ANTLR で自動生成したファイルを格納しています。また、java/ ディレクトリ下に解析したいファイルを置き、myextend/ ディレクトリ下にANTLRを呼び出すProcessor、イベントを受け取るListener、Nodeツリーを構成する各種クラスを配置しています。
スポンサーリンク
独自拡張プログラムの使い方
使い方はいたってシンプル。java/ ディレクトリ下に構文解析したいJavaファイルをコピーし、以下のコマンドを実行します。
プログラムを実行すると、ast_main.py のファイルがあるディレクトリ直下に、CSVファイルが出力されます。
command
$ py ./ast_main.py
メイン処理
main 関数のある処理です。
java/ ディレクトリ内にあるファイルを検索し、それぞれのファイルを構文解析する子プロセスを立ち上げます。
子プロセスが構文解析した結果を、ast_main.py と同じディレクトリにCSVファイルで出力していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import os import subprocess import sys from pathlib import Path from myextend.AstProcessor import AstProcessor from myextend.StatementListener import StatementListener class FileFinder(): def __init__(self, path, filter): self.obj = Path(path) self.filter = filter self.list = [] def exec(self): result = self.obj.glob(self.filter) for f in result: self.list.append(str(f)) def getResultByList(self): return self.list def getFileName(f): start = f.rfind("\\") + 1 end = f.rfind(".") return f[start:end] def mainProcess(): fl = FileFinder("java/", "**/*.java") fl.exec() files = fl.getResultByList() for f in files: fname = getFileName(f) + ".csv" with open(fname, "w") as fd: cmd = ["py", sys.argv[0], f] subprocess.run(cmd, stdout=fd) def childProcess(filePath): AstProcessor(StatementListener()).execute(filePath) if __name__ == '__main__': if len(sys.argv) is 1: mainProcess() else: childProcess(sys.argv[1]) |
mainProcess() の処理概要
- java ファイルの検索
- 見つかったjavaファイル毎に出力用のCSVファイルをオープン
- javaファイルの構文解析をする子プロセスのstdoutにCSVファイル識別子を指定して立ち上げ
childProcess() の処理概要
- 独自に実装したListenerのインスタンスを生成 (StatementListener)
- 後術するAstProcessorのインスタンスを生成
- 構文解析対象のファイルパスを引数として AstProcessor.execute() を実行 (構文解析開始)
スポンサーリンク
AST構文解析を実行する処理
独自に実装したListenerを登録し、ANTLR の構文解析エンジンを動かす処理です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from antlr4 import FileStream, CommonTokenStream, ParseTreeWalker from ast.JavaLexer import JavaLexer from ast.JavaParser import JavaParser from pprint import pformat class AstProcessor: def __init__(self, listener): self.listener = listener def execute(self, input_source): parser = JavaParser(CommonTokenStream(JavaLexer(FileStream(input_source, encoding="utf-8")))) walker = ParseTreeWalker() walker.walk(self.listener, parser.compilationUnit()) |
execute() の処理概要
- 構文解析対象のファイルを引数にJavaLexerのインスタンスを生成
- Lexerのインスタンスを引数にJavaParserのインスタンスを生成
- ParseTreeWalkerのインスタンスの walk() メソッドを呼び出して構文解析を実行
独自Listenerの実装
ソースコードを構文解析する際の重要なポイントとなる独自Listenerの実装について説明します。
実装方法はいたってシンプル。
- ANTLRが自動生成したJavaParserListenerを継承して独自のListenerを実装
- 必要なJavaParserListenerの関数をオーバーライドして処理を実装
- Listenerは構文解析エンジンの動きを意識して実装する必要がある
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
from ast.JavaParserListener import JavaParserListener from ast.JavaParser import JavaParser from myextend.Node import Node from myextend.NodeTree import NodeTree from myextend.IfStatementNode import IfStatementNode class StatementListener(JavaParserListener): def __init__(self): super().__init__() self.depth = -1 self.nodeTrees = [] self.call_methods = [] self.current_method = "" def myBegin(self, ctx, isSkip:bool=False): self.call_methods = [] self.current_method = \ "L.{0} {1} {2}".format(ctx.start.line, ctx.getChild(0).getText(), ctx.getChild(1).getText()) if isSkip == False: self.current_method += "(" params = self.parse_method_params_block(ctx.getChild(2)) for i in range(len(params)): if i != 0: self.current_method += ", " self.current_method += "{0} {1}".format(params[i]['paramType'], params[i]['paramName']) self.current_method += ")" pass self.nodeTrees.append(NodeTree(self.current_method)) def myExit(self, ctx): print(self.nodeTrees[-1].getConditionList(), end="") def enterConstructorDeclaration(self, ctx:JavaParser.ConstructorDeclarationContext): self.myBegin(ctx, isSkip=True) def exitConstructorDeclaration(self, ctx:JavaParser.ConstructorDeclarationContext): self.myExit(ctx) def enterMethodDeclaration(self, ctx:JavaParser.MethodDeclarationContext): self.myBegin(ctx) def exitMethodDeclaration(self, ctx:JavaParser.MethodDeclarationContext): self.myExit(ctx) def enterBlockStatement(self, ctx:JavaParser.BlockStatementContext): self.depth += 1 def exitBlockStatement(self, ctx:JavaParser.BlockStatementContext): self.depth -= 1 def enterStatement(self, ctx:JavaParser.StatementContext): if self.nodeTrees[-1].isSupportedStatement(ctx): self.nodeTrees[-1].appendChild(ctx) def exitStatement(self, ctx:JavaParser.StatementContext): if ctx.SWITCH(): self.nodeTrees[-1].popStackSwitchNode() def enterSwitchLabel(self, ctx:JavaParser.SwitchLabelContext): self.nodeTrees[-1].appendSwitchLabel(ctx) def parse_method_params_block(self, ctx): params_exist_check = int(ctx.getChildCount()) result = [] if params_exist_check == 3: params_child_count = int(ctx.getChild(1).getChildCount()) if params_child_count == 1: param_type = ctx.getChild(1).getChild(0).getChild(0).getText() param_name = ctx.getChild(1).getChild(0).getChild(1).getText() param_info = { 'paramType': param_type, 'paramName': param_name } result.append(param_info) elif params_child_count > 1: for i in range(params_child_count): if i % 2 == 0: param_type = ctx.getChild(1).getChild(i).getChild(0).getText() param_name = ctx.getChild(1).getChild(i).getChild(1).getText() param_info = { 'paramType': param_type, 'paramName': param_name } result.append(param_info) return result |
スポンサーリンク
enterConstructorDeclaration() / enterMethodDeclaration() の処理概要
- 1つのコンストラクター or メソッドの解析が始まるタイミングで呼び出されるListener
- myBegin() を呼び出して行番号、メソッド名、引数、戻り値などの情報を保存
- NodeTree のインスタンスを生成し、配列へつなげて保存
exitConstructorDeclaration() / exitMethodDeclaration() の処理概要
- 1つのコンストラクター or メソッドの解析が終了したタイミングで呼び出されるListener
- myExit() を呼び出して、ノードツリー(コンストラクター or メソッド内の全ての条件分岐)を出力
enterBlockStatement() / exitBlockStatement() の処理概要
- Javaの文法上 {...} が必要となるブロック内の解析開始 / 終了する際に呼び出されるListener
- ブロックの開始 / 終了時には階層(Nesting)が変わるためカウント
- 今回は使用していません
enterStatement() の処理概要
- statement の解析開始時に呼び出されるListener
- 本独自プログラムで解析対応しているstatementかどうかを確認
- 対応している場合、NodeTreeリスト末尾の NodeTree.appendChild() を呼出す
- その後、statementの識別や、解析しているメソッドのNodeTreeを構成していく
exitStatement() の処理概要
- statement の解析終了時に呼び出されるListener
- Switch 文の解析時のみ普段と異なる動きをするため、ここで Switch文に対応するNodeの終了処理を実施
enterSwitchLabel() の処理概要
- Switch の case 文を解析開始した時に呼び出されるListener (普段と異なる動きとはコレのこと)
- NodeTree 末尾の appendSwitchLabel() を呼出し、case 文に対するNodeを生成
スポンサーリンク
独自NodeTreeの実装
ANTLRが生成した構文解析スクリプトの中でも、実はASTのノードツリーを持っています。
しかし、余分なものが含まれていたり、手を加えるのにRuntimeを改修しなければいけないので、Listenerの呼出しを契機に独自NodeTreeを構築しています。
NodeTreeクラス
- インスタンス
StatementListenerがメソッドごとにインスタンスを生成します - isSupportedStatement()
独自拡張で対応しているStatementか否かを確認します - getText()
繋がっている全Nodeの情報を文字列で出力します - getConditionList()
繋がっている全Nodeの情報をCSVで出力します - appendChild()
StatementListenerで構文解析エンジンから新たなStatementを受け取った時に呼び出されます
どこのNodeに接続すればよいかを判断し、子NodeのappendChild()を呼出します
Nodeクラス
- インスタンス
他の全Nodeの基底クラスになっています。また、代入などの実際の実行ステップの内容を保持するNodeです。 - getText()
自Nodeの情報を文字列で出力します (親Nodeから順に呼び出されます) - getConditionList()
自Nodeの情報をCSVで出力します (親Nodeから順に呼び出されます) - getRootTree()
親のNodeTreeを探す時に呼び出します。子Nodeから親を辿る場合に使用します - getTreeInfoList()
構文解析エンジンが持っているNode情報から、独自拡張部分に最適な情報を生成します
IfStatementNodeクラス
- インスタンス
If文のstatementが見つかった際に生成されます - getText()
If文の条件を出力し、TrueとFalseの分岐に繋がっているNodeのgetText()を呼出します - getConditionList()
If文の条件を出力し、TrueとFalseの分岐に繋がっているNodeのgetConditionList()を呼出します - appendChildByInfo()
Node.getTreeInfoList()で生成した情報に基づいて、Nodeを自Nodeに追加するか、子Nodeに追加します - appendActionByInfo()
代入などの実際の実行ステップを自Nodeに保持します
スポンサーリンク
SwitchStatementNodeクラス
- インスタンス
switch文のstatementが見つかった際に生成されます - getText()
switch文の条件を出力し、子Nodeに繋がっているCaseNodeのgetText()を呼出します - getConditionList()
switch文の条件を出力し、子Nodeに繋がっているCaseNodeのgetConditionList()を呼出します - appendChildByInfo()
Node.getTreeInfoList()で生成した情報に基づいて、Nodeを自Nodeに追加するか、子のCaseNodeに追加します - appendCase()
case分岐が見つかった場合に呼び出され、自NodeのCaseリストに追加します
CaseNodeクラス
- インスタンス
case分岐、またはdefaultが見つかった場合に、SwitchStatementNodeクラスに生成されます - getText()
保持している子NodeのgetText()を呼出します - getConditionList()
保持している子NodeのgetConditionList()を呼出します - appendChild()
Nodeを自Nodeに追加します
各クラスのソースコードは、本記事の最下部にあります。
出力されたCSVファイルを整形するVBAプログラム
VBAマクロでは、出力されたCSVファイルに対して、以下の整形を行います。
- 各セル幅の統一と、背景色の設定、フィルターの有効化
- 条件判定の後に実行する内容が所定の関数呼び出し(例えば、Log出力)の場合、B列にLOGと出力
※フィルターをかけることで、実際に有効なロジックが見えやすくなります - メソッド名の背景色を設定、「条件」と「実行ロジック」の列を決定
- IF文、ELSE文、SWITCH文に対して背景色を設定し、空白セルに灰色を設定
VBAプログラムのインターフェイス(Excel)
上記の整形を行うためのインターフェイスとして、以下のようにしました。

整形の手順
- Pythonで出力したCSVファイルを「MyTest」としてシートにコピーする
- 出力用の新規シート「MyTest.mod」を挿入する
- C2セルとC3セルに、入力するCSVのシート名、出力先の新規シート名を入力する
- ALLボタンをクリック
独自拡張したPythonプログラムと整形用VBAプログラム
プログラムの続きは note に記載しています。「LINK はコチラ」
以上、「【保守】Javaソースコードから状態遷移表を作成する方法」でした。